
Photo by Lukas
AI brings new opportunities for building products, but also some new challenges and pitfalls in the product management process. Several factors require special consideration when building AI products, ranging from technology constraints, data and privacy considerations, as well as legal and regulatory issues.
In this article, we will be focussing on aspects related directly to the core product and technology and, more specifically, those related to bringing innovative products to market. We will also discuss the 4 key challenges of creating AI products:
- Challenge 1: Technology readiness
- Challenge 2: Project vs product business
- Challenge 3: Building a platform versus going vertical
- Challenge 4: Data
Challenge 1: Technology readiness
The number one factor to consider when discussing product management and AI is technology readiness. While progress in AI technology (including computer vision, natural language processing (NLP), etc.) has been astonishing, we are still a long way from solving many of the fundamental scientific and technical problems. This means that any product leveraging AI at its core must explore the boundary of what’s feasible today or in the short-term future if the product is to get adopted by buyers and drive revenue. In other words, the role of product management is to find the intersection of what is feasible from a technology standpoint and what offers value for the business:
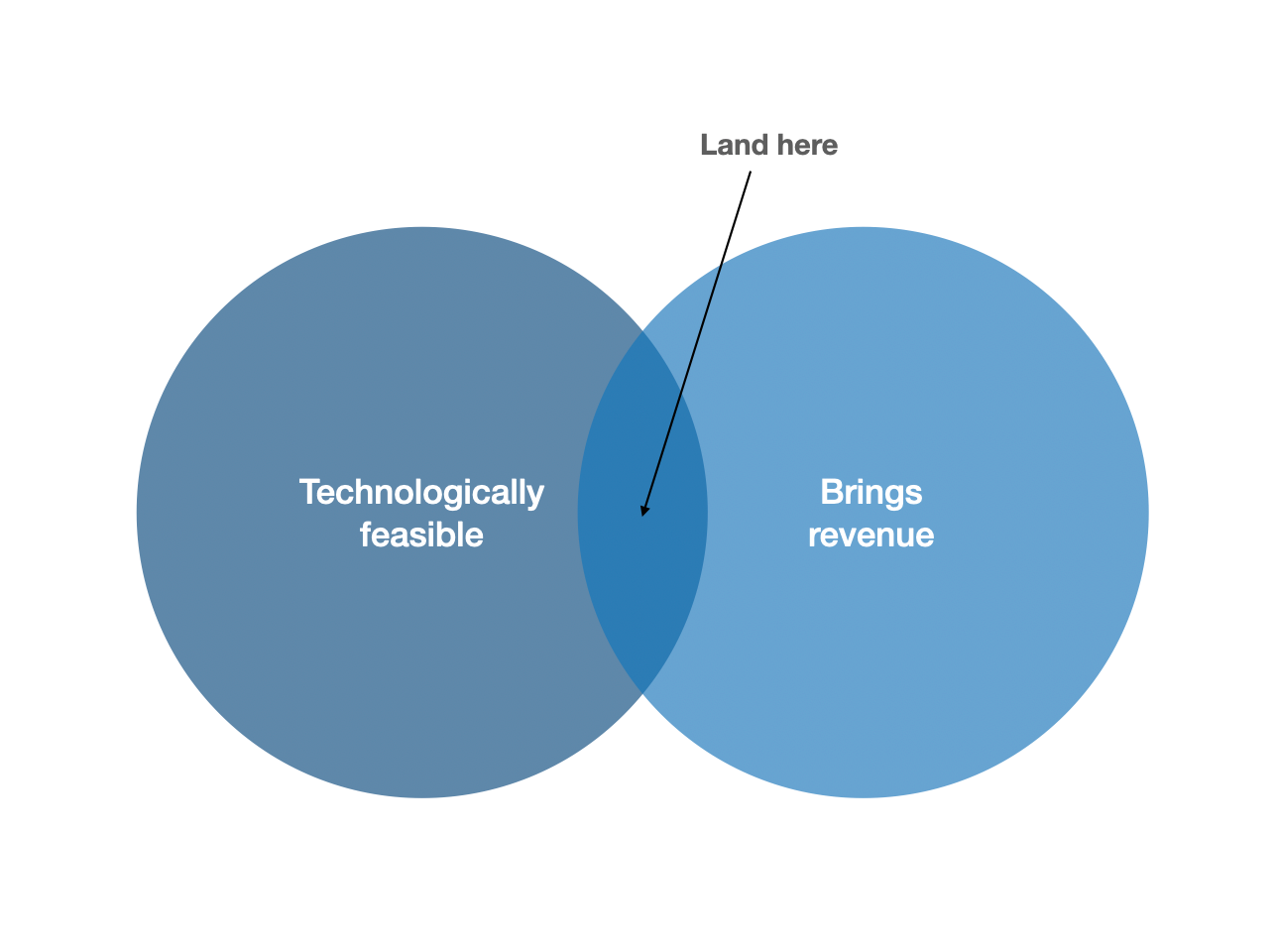
While finding a solution to this problem is true for any tech product, the challenges found in cutting-edge technology are more fundamental and less easy to solve. For example, building a scalable commerce site poses many technological challenges, but we know it can be done and we can rest assured in the knowledge that others have successful accomplished it in the past. In contrast, consider building a visual search engine for every object in the world: it is not obvious if today’s technology can solve this. In many ways, we would be unsure of how feasible a project of this scale would be with no reference point to start from.
To address a challenge of this magnitude, we would need to carefully address and evaluate individual use-cases for their technical feasibility and their business potential, and rank them accordingly (We will explore this further when we look at a case study based on wine label recognition). Furthermore, building proofs of concept (POCs) and incremental testing and development are even more crucial with cutting edge products than it is with “standard” products. With no point of reference to compare against, checking that goals are being met is vital to ensure that time and money are not being wasted.
Generally, development cycles for AI technology are long, hence it is important to break them down into the smallest pieces possible with as many POC iterations as possible to ensure success.
Challenge 2: Project vs product business
The second challenge is in many ways intertwined with the first one. When working incrementally on a new product, it’s often useful to work closely with key customers or users. But this can present its own problems, and each customer or user will come with their own ideas and particular requirements for their specific use-case or business. While this is natural for any business, the costs of developing a particular AI solution to meet their needs can be high. Often an AI algorithm will need special tweaking to make it work correctly for a particular use-case or niche. This usually means adding additional training data and re-training algorithms to create dedicated models for each customer or producing a particular treatment for the output and its format.
One way that is often used to deal with this level of customization is to charge the customer for the extra effort required. The issue with this is that you may find yourself in the business of delivering bespoke customer projects rather than building a scalable AI business. There is no silver bullet solution to this challenge. It requires an awareness of the trade-offs required and smart navigation of the fine line between satisfying customers and working towards a scalable business. In the best-case scenario, customization made for a client (e.g. a dedicated ML model) can later be reused and applied to other customers within the same sector or niche.
The bottom line is that not only do you need to find the intersection of technical feasibility and business viability, you also need to optimize for scalability at the same time. This narrows our area of success further:
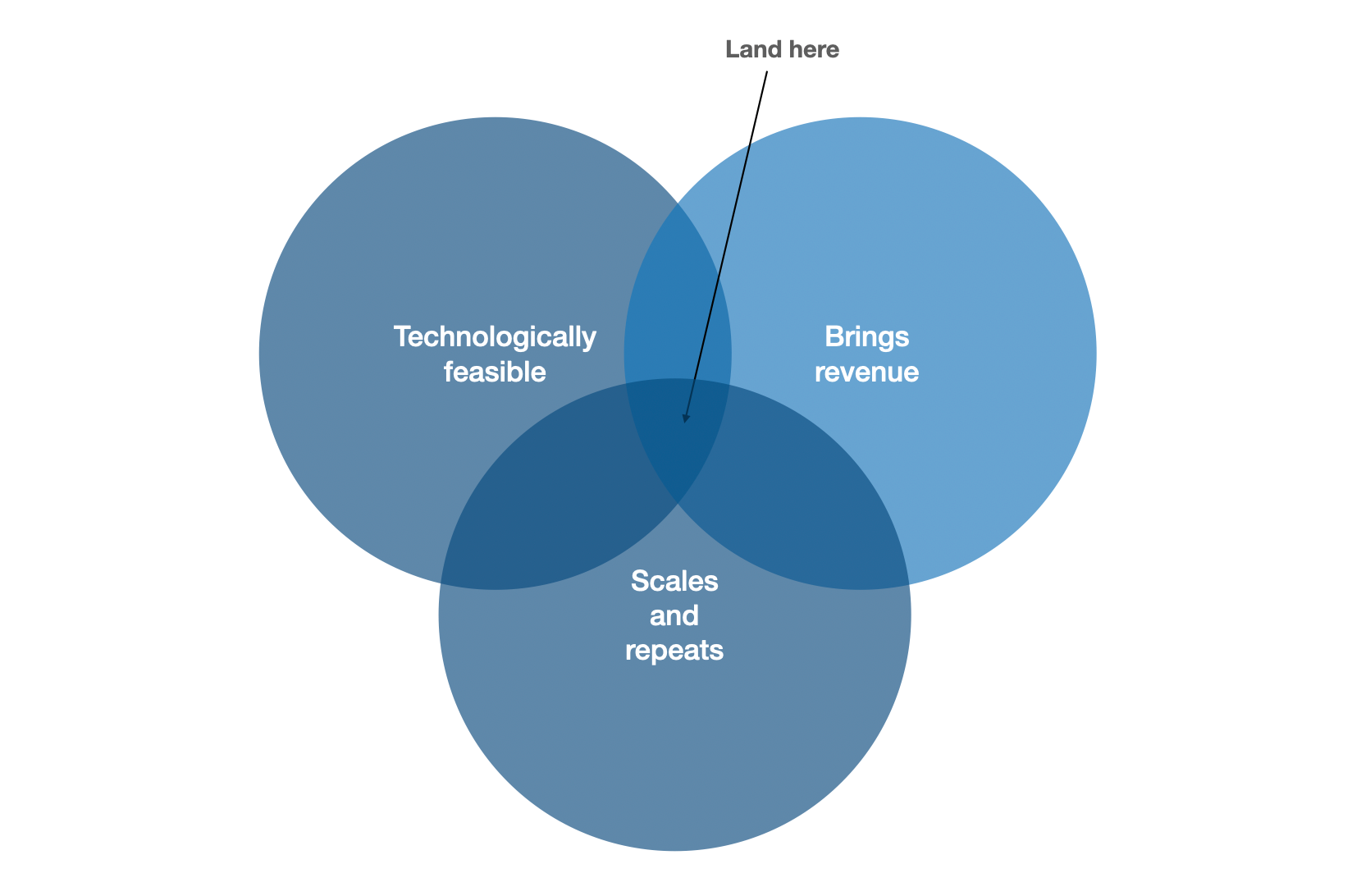
Challenge 3: building a platform versus going vertical
Once you are focused on building a company who specializes in AI, you will be faced with another choice: building a platform that works for many use-cases or focusing on one particular vertical application. For example, when providing an AI-powered document summarization service, do you provide a general-purpose platform, or do you focus on a specific application such as legal documents?
There is a trade-off here and there is typically a significant investment required in data collection, data annotation, training algorithms (GPU resources), etc. to get an AI product to work well. This may mean that it is easier to focus on a particular vertical application since it constrains the variety of data required for success. On the flip side, when focusing on just one vertical, you may need to invest far beyond the core AI service to build an attractive product for customers. In the legal document example above, you may find that you end up becoming a full-blown legal document service who just so happens to use some AI features - and not an AI company with legal document summarization as one of its use-cases. Neither of these is necessarily better or worse, but they are fundamentally different products and require fundamentally different business models.
When going vertical you also need to pick a specialisation that will (hopefully) bring in revenue. There are inherent risks associated with focusing on just one application compared to going the platform route and creating technology that covers a lot of different use-cases. That’s not to say going the platform route is risk free and there is a real danger of spreading yourself too then by trying to do too much. This can lead to a weak product that customers don’t want.
Choosing which way to go isn’t easy but there are a couple of strategies that can be used to get “the best of both worlds” (both platform and vertical):
- Partner with a key customer in a particular domain to cover one vertical. Agree on a revenue share deal, but make sure to have a (lower) base fee that covers the risk. Choose your partner wisely, and then cooperate very closely.
- Spin-out separate businesses in verticals. In the best case you can even develop an “AI studio” business: that is a business that spins out several sub-businesses, which benefit from shared resources and knowledge.
Challenge 4: Data
The main draw of using current machine learning (ML) algorithms (deep learning algorithms) is that they continuously get better as they are fed more (labelled) data. In contrast, before the deep learning revolution, throwing more (labelled) data at the problem had little effect on the result or performance. While it is convenient that performance can be improved just by adding more data, it also means that a huge amount of resources need to be spent on collecting and labelling data. Whole companies are built on this service. Furthermore, big tech players with deep pockets and massive infrastructure have a major advantage over smaller players in the market or those looking to break into it.
In short: data is essential, and two things need to be considered when building a data pipeline for your AI product:
- How to get the initial raw data.
- How to label it.
If we look at the legal documents example again, we are left with a number of questions. Firstly, where do you get a huge corpus of hundreds of thousands of legal texts? Secondly, when you do have them how do you label them? Do you need expert labellers with a background in Law? Or can the problem be simplified so that it can be farmed out to a large crowd of “clickworkers”? A third aspect to consider is what you need to do to ensure diversity of content and avoid bias in the training datasets?
Possible solutions that ensure that you not only collect the right data, but have it labelled correctly for your AI product include:
- Incremental labelling with a feedback loop: With this method you build an initial version of your product, collect failure cases, and retrain algorithms with the new data including similar cases. You can then ask users for feedback on the results and use this to refine the data collection process.
- Ensure that you acquire the correct initial database: This can be accomplished by forming partnerships with clients who own the data you need. Be creative in how you build the initial version (or versions) of the product and incentivize users to contribute data.
- Don’t use an algorithm in initial builds and have humans manually label the queries.
In summary, integrating AI into your products comes with new tasks and new challenges for any product manager. I have addressed some of the key areas in this article. To complement the solutions described above with more practical examples, we intend to create a follow-up post that will look at the case-studies of two successful AI start-ups.
Please sign up for our newsletter if you’d like to be notified when this happens.